
The future of AI...
instantaneous inference

Taalas came out of stealth a few days ago, unveiling their custom chip for running AI models. They demoed a chip with the weights of a Llama 3.1 8b parameter model etched onto the silicon itself, allowing for ultra fast inference and responsiveness.

Below is a demo of the model, you can also try it out at chatjimmy.ai (not sure why they called it that):
It is hard to understate how insane this is. Cerebras was previously the leading provider for fast inference, but this absolutely dominates toks/second benchmarks:
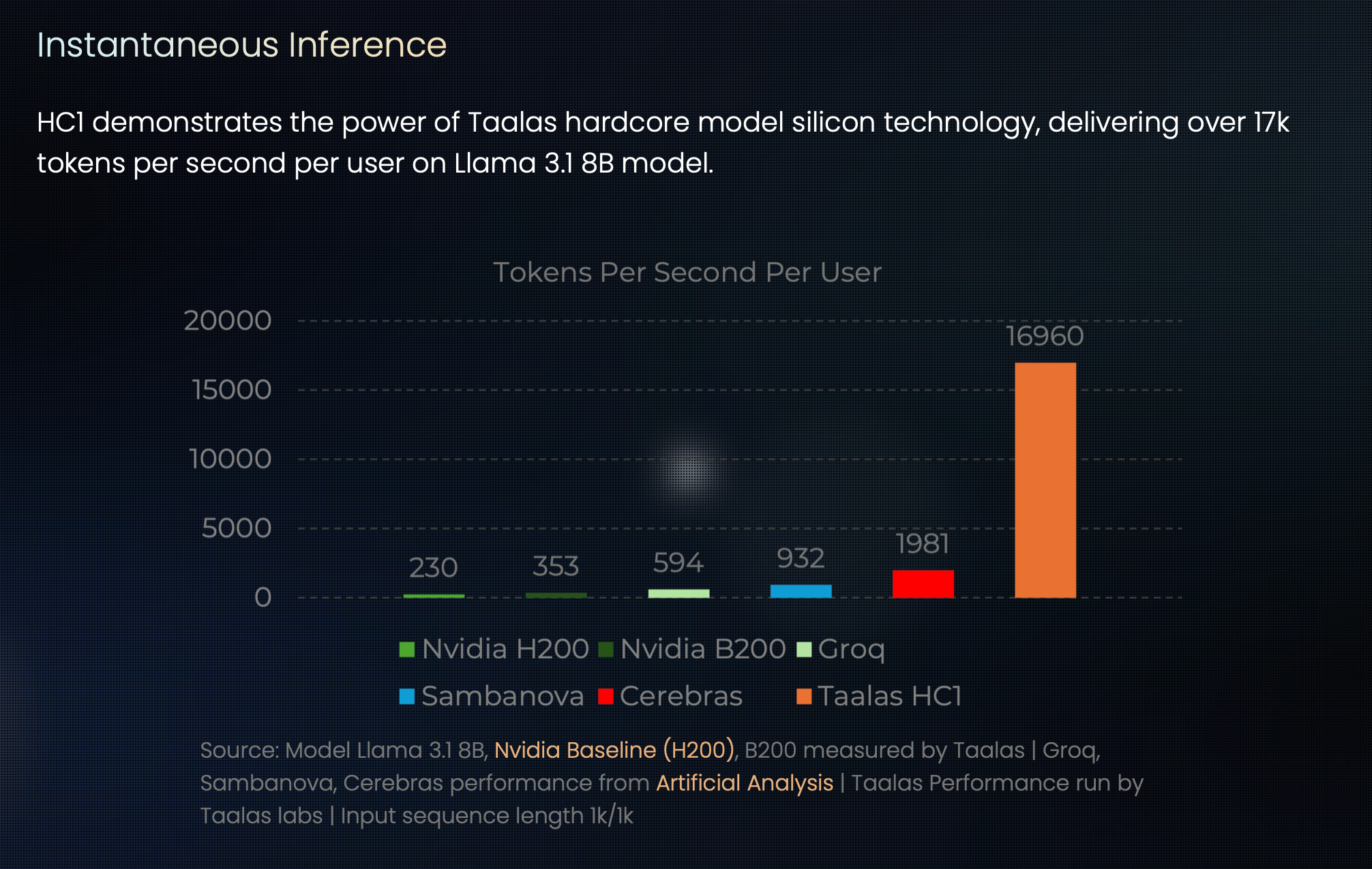
For me this was another ‘deepseek’ type moment, where despite keeping track the frontier of AI daily and having well-informed intuitions, I was genuinely astounded when I tried the demo.
It’s extremely hard to comprehend the level of intelligence and speed that’s coming.
The Llama 3.1 8b model isn’t smart, but it’s decent enough for a lot of tasks that AI is used for. This combined with the research into recursive LLMs (getting a tiny model to iterate on itself for massive increases in performance) might genuinely be how LLMs get integrated into hardware in the future.
There are a few downsides of this compared to other providers:
The model weights are etched into the silicon itself, meaning you cannot load another model onto the chip and update it. This allows for massive performance and optimisation gains at the cost of customisability and updatability.
Currently the Llama model has been quantised (made smaller and dumber) to fit onto the chip. Future models will use better/lesser quantisations to improve intelligence.
Llama 8b is pretty small compared to the Qwen3 235b model that Cerebras supports. I think the speed more than makes up for it, it’s almost trivial to search the entire solution space when you have ~17000 toks/second.
Overall I’m extremely excited for this and definitely urge all of you guys to try it out! If you do, comment and let me know what you think and what your impressions are!
Thanks and don’t forget to like and subscribe!!